
Jan 20, 2024
Applications built on procedural noise often rely on a network of interconnected noise channels. In certain situations, some of these layers may share a common frequency and differ only in their seeds. This is notably prevalent in cave tunnel generation, biome map sampling, and multi-color blending, where the target patterns can depend fundamentally on the interplay between multiple individual values. As the complexity of a generator grows, so too can the importance of optimization. In this article, I will demonstrate an approach through which multiple seeds of noise can be evaluated using a single efficient function call.
Read More
Jan 16, 2022
In The Perlin Problem: Moving Past Square Noise, I shed light on the axis alignment problems Perlin and related noises carry in their unmitigated forms. I then covered two key tools we have to address them: Simplex-type noise and Domain Rotation. Here, I will recommend a set of best practices we can employ to improve the information we contribute to the field, keeping our content as helpful as possible.
Read More
Jan 16, 2022
Noise plays an elemental role in many genres of procedural generation. One algorithm in particular, Perlin noise, has dominated the conversational spotlight, but it suffers a critical flaw: visible axis alignment. Newer approaches exist which address this problem, but such biased noise still sees widespread use where it may not be the right choice. In this article, I will dive deep into this issue and cover two of our most practical options now.
Read More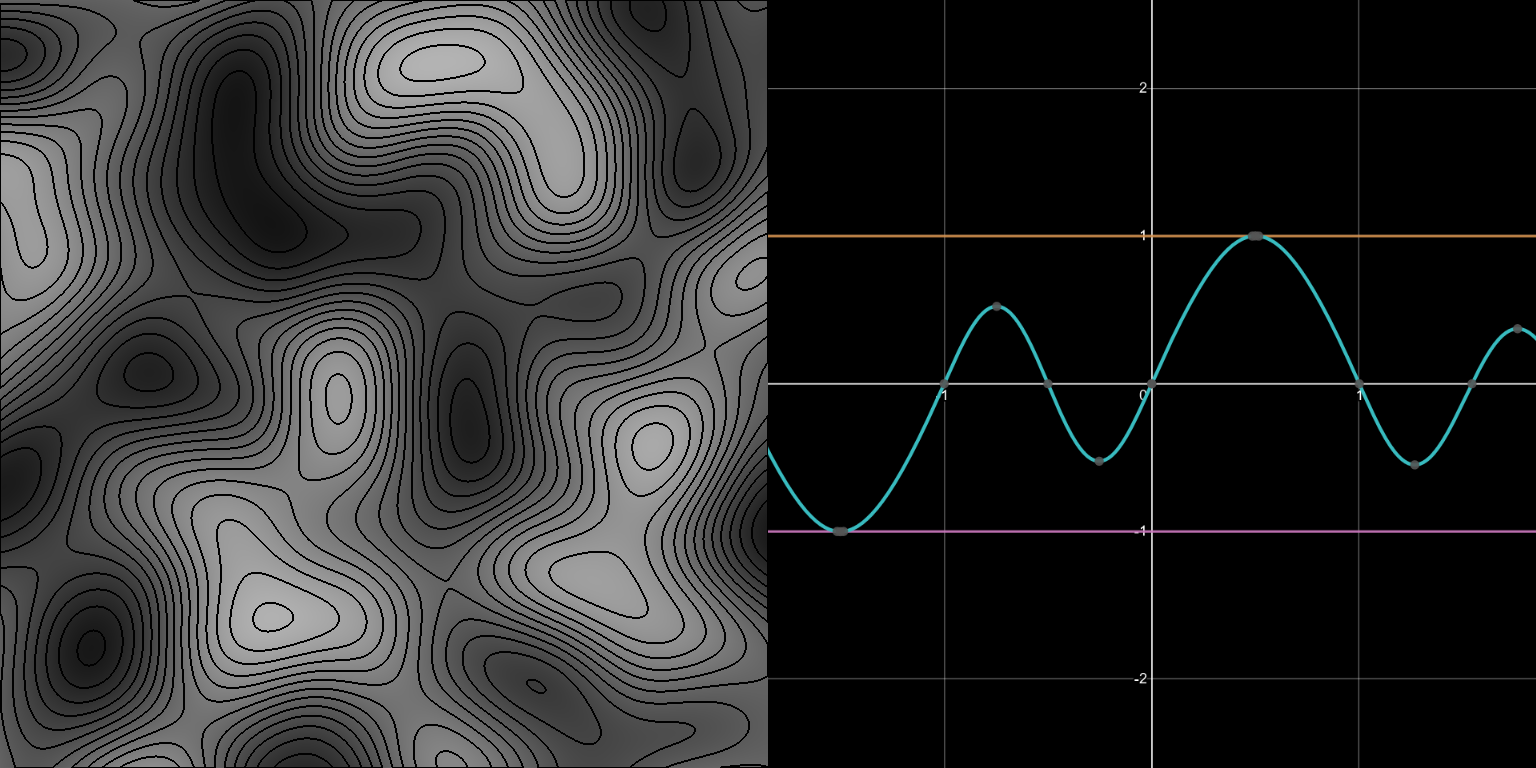
Mar 22, 2021
One of the trickiest steps that can be involved in implementing noise algorithms is to make their output fit tightly into certain bounds. Generally, this is accomplished by determining the min and max of the unmodified noise as accurately as possible, then rescaling the output to [-1, 1]. There is not always a nice formula to compute these values, and brute-force approaches can be unreliable. In this article, I will describe the tools I created to find these values in common gradient-based noises, and the techniques they employ.
Read More
Mar 13, 2021
Many games that feature procedurally generated worlds divide the worlds into individual biomes. The biomes often have separate terrain or features, which need to be blended smoothly at the borders. Most of the common or intuitive solutions suffer one of two shortcomings: they’re slow, or they have visible grid patterns. In this post, I will demonstrate a method which avoids the latter with a much better tradeoff in the former. The method involves two main components: Voronoi-noise-style data point distribution, and normalized sparse convolution.
Read More